Latest developments in Large Multimodal Models (LMMs) have broadened their capabilities to include video understanding. Specifically, Text-to-video (T2V) models have made significant progress in quality, comprehension, and duration, excelling at creating videos from simple textual prompts. Yet, they still frequently produce hallucinated content that clearly signals the video is AI-generated.
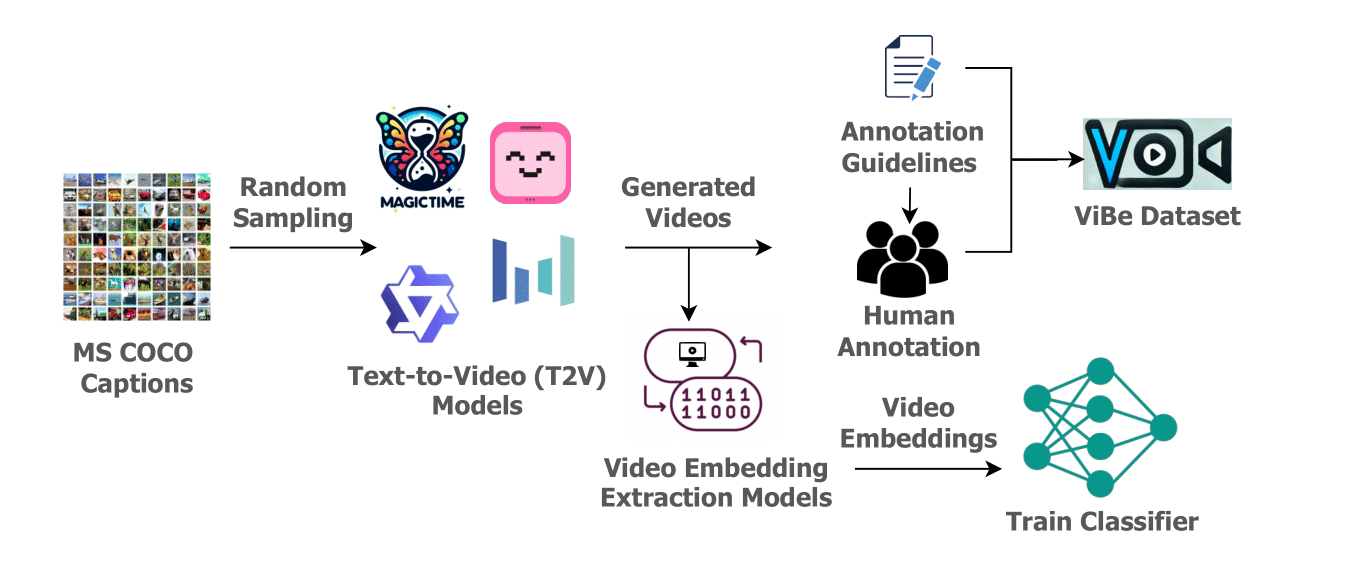
We introduce ViBe: a large-scale Text-to-Video Benchmark of hallucinated videos from T2V models. We identify five major types of hallucination: Vanishing Subject, Numeric Variability, Temporal Dysmorphia, Omission Error, and Physical Incongruity. Using 10 open-source T2V models, we developed the first large-scale dataset of hallucinated videos, comprising 3,782 videos annotated by humans into these five categories.
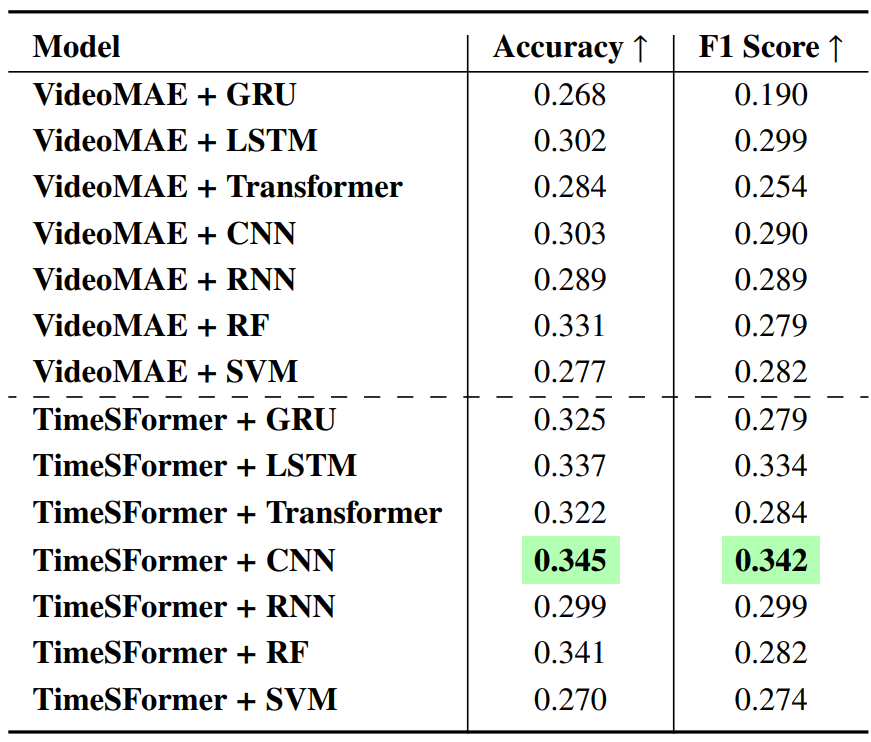
ViBe offers a unique resource for evaluating the reliability of T2V models and provides a foundation for improving hallucination detection and mitigation in video generation. We establish classification as a baseline and present various ensemble classifier configurations, with the TimeSFormer + CNN combination yielding the best performance, achieving 0.345 accuracy and 0.342 F1 score. This benchmark aims to drive the development of robust T2V models that produce videos more accurately aligned with input prompts.
To construct the ViBe dataset, we selected 700 random captions from the MS COCO dataset, which is known for its diverse and descriptive textual prompts, making it an ideal resource for evaluating the generative performance of T2V models. These captions were then used as input for ten distinct open-source T2V models, chosen to represent a variety of architectures, model sizes, and training paradigms. The specific models included in the study were:
| Name | Source | Link |
|---|---|---|
| AnimateLCM | HuggingFace | View |
| AnimateLightning | HuggingFace | View |
| AnimateMotionAdapter | HuggingFace | View |
| HotShotXL | HuggingFace | View |
| MagicTime | GitHub | View |
| Show1 | GitHub | View |
| MSB1.7b | HuggingFace | View |
| zeroscope_576w | HuggingFace | View |
| zeroscope_XL | HuggingFace | View |
| MORA | GitHub | View |
@article{rawte2024vibe,
title={ViBe: A Text-to-Video Benchmark for Evaluating Hallucination in Large Multimodal Models},
author={Rawte, Vipula and Jain, Sarthak and Sinha, Aarush and Kaushik, Garv and Bansal, Aman and Vishwanath, Prathiksha Rumale and Jain, Samyak Rajesh and Reganti, Aishwarya Naresh and Jain, Vinija and Chadha, Aman and others},
journal={arXiv preprint arXiv:2411.10867},
year={2024}}